

導入
紙の書籍や資料をPDF化する「自炊(電子化)」は、近年さらに進化しています。
特に注目されているのが、OCR(光学文字認識)データとAIの組み合わせです。
これにより、単なるデータ保存だけでなく、
- 内容の要約
- 検索性の向上
- 知識の活用
といった、新しい使い方が可能になりました。これまで眠っていたOCRデータは、「瞬時に要約され」「必要な情報だけ抽出し」「複数資料を横断して分析できる」強力な情報資産へと変わります。
本記事では、自炊OCRデータ×AIで何ができるのか、そしてどのAIツールを選べばよいのかを実務視点でわかりやすく解説します。各AIツールの比較表やおすすめのOCRツールも紹介するので、ぜひ参考にしてください。
今回OCRデータの検証として利用するAIツール一覧
自炊OCRデータと相性の良いAIツール 比較表
PDF化した自炊OCRデータと相性の良いAIツールについて、性能・特徴を一覧で比較しました。
自炊OCRデータと相性の良いAIツール
ChatGPT
- URL:https://chatgpt.com/
- 特徴:PDFをアップロードして直接質問可能
- 強み:分析・要約・業務活用に強い
👉 おすすめ用途
- 業務資料の整理
- FAQ生成
- データ抽出
実際のPFDをアップロードし検証
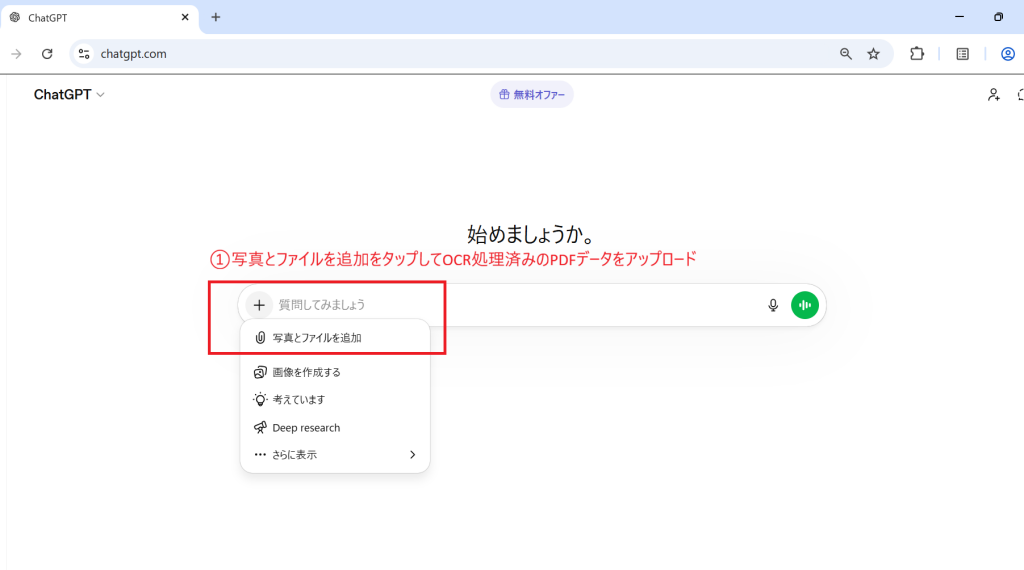
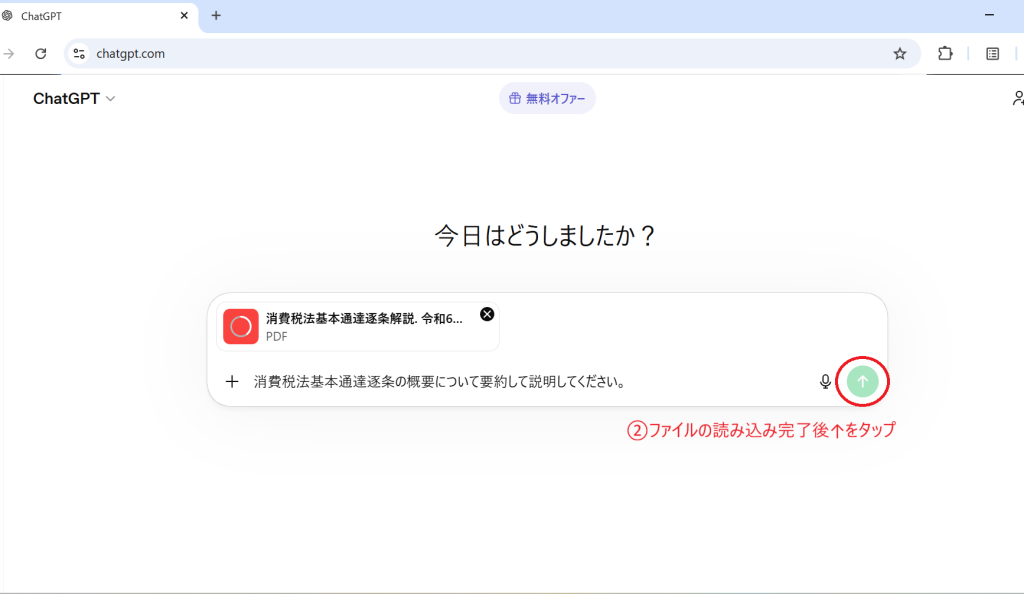
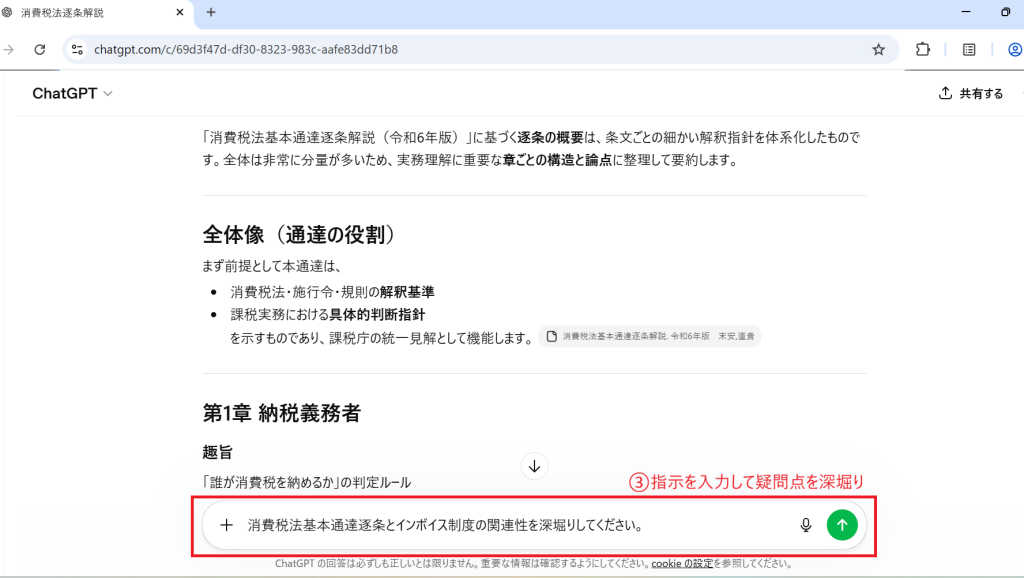
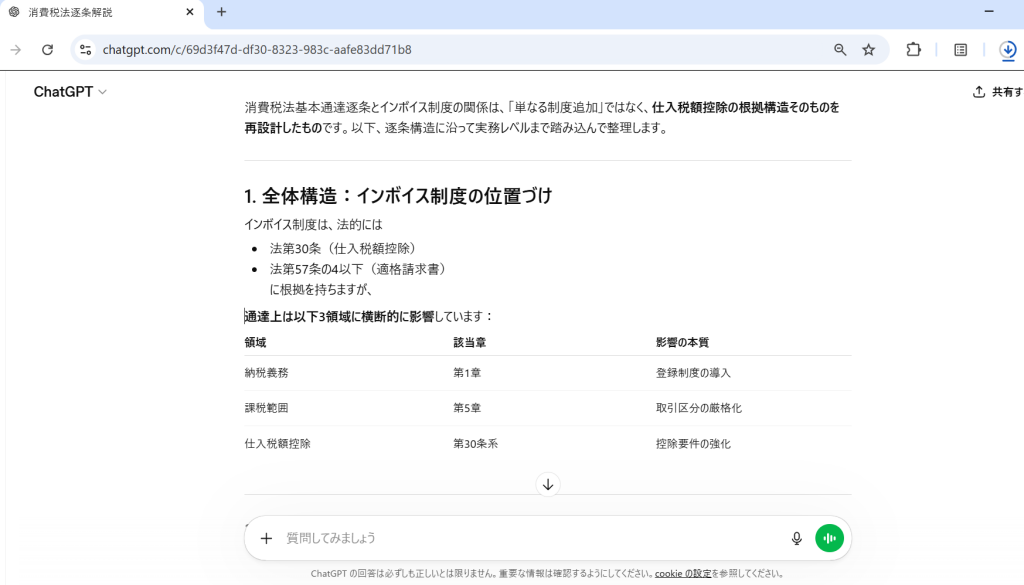
このように箇条書きや表形式によって情報が端的に整理・構造化されていて、複雑な制度についてもわかりやすく整理されています。複雑な指示にも対応していて文脈理解が強く、会話形式で気になったところをスムーズに深堀りでき、思考の解像度を飛躍的に高めてくれる心強いAIです。
一方でコンテキストウィンドウには限界があり、会話が続くと古い情報の参照優先度が低下します。会話による情報の整理・分析・アイデア出しは得意分野ですが、長いやり取りでは重要な前提・条件の再提示が必要です。
\早速 読む→聞くを試してみる/
Claude
- URL:https://claude.ai
- 特徴:長文処理に強く、大量のPDFでも対応可能
- 強み:文脈理解が自然で精度が高い
特長
最大の強みは、他を圧倒する長文処理能力にあります。大容量のコンテキストウィンドウを備えているため、書籍一冊分のOCRデータであっても丸ごと読み込み、情報の論理的なつながりを保ったまま的確に要約や整理を行うことが可能です。
構造が複雑な専門書や長大な資料を処理させても、文脈を見失うことはありません。さらに、出力される文章はまるで人が直接書いたかのような自然な仕上がりであり、最小限の手直しでそのまま実務資料として活用できる品質を誇る点は、他のAIにはない際立った特長と言えます。
膨大な自炊データを単なる保存にとどめず、本格的な知識資産として活用したい方に、特におすすめできる存在です。
👉 おすすめ用途
- 書籍の読み込み
- 長文資料の要約
実際のPFDをアップロードし検証
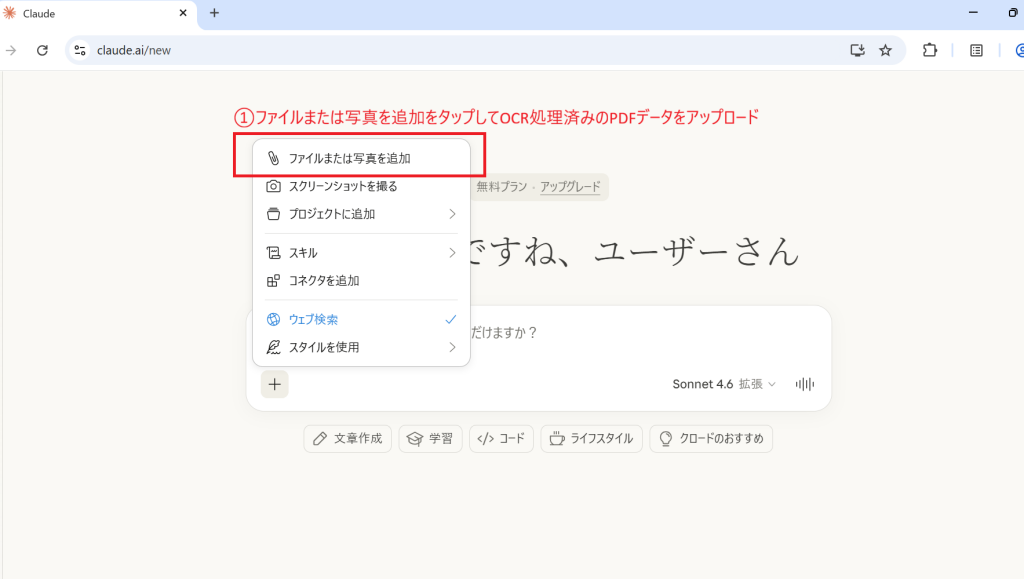
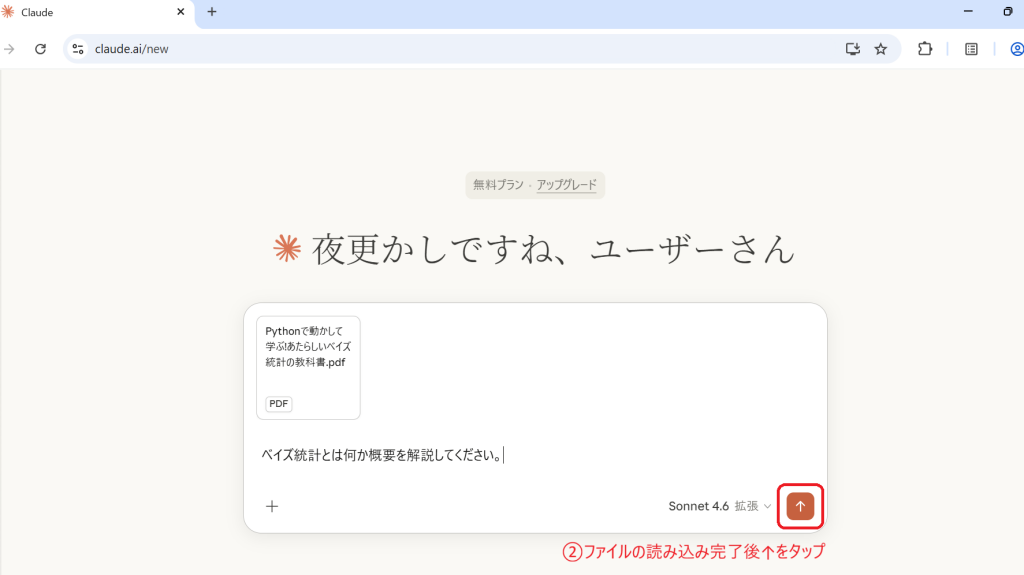
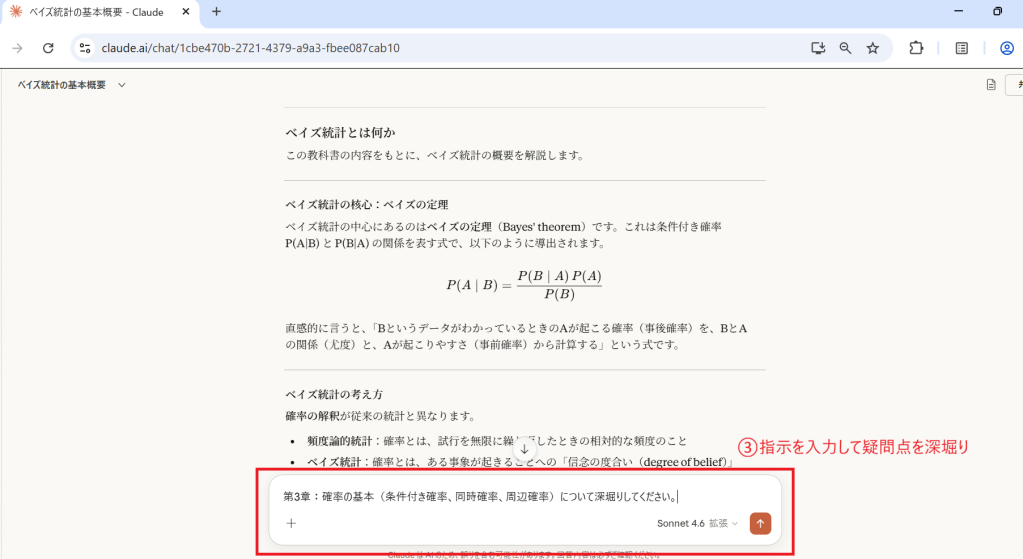
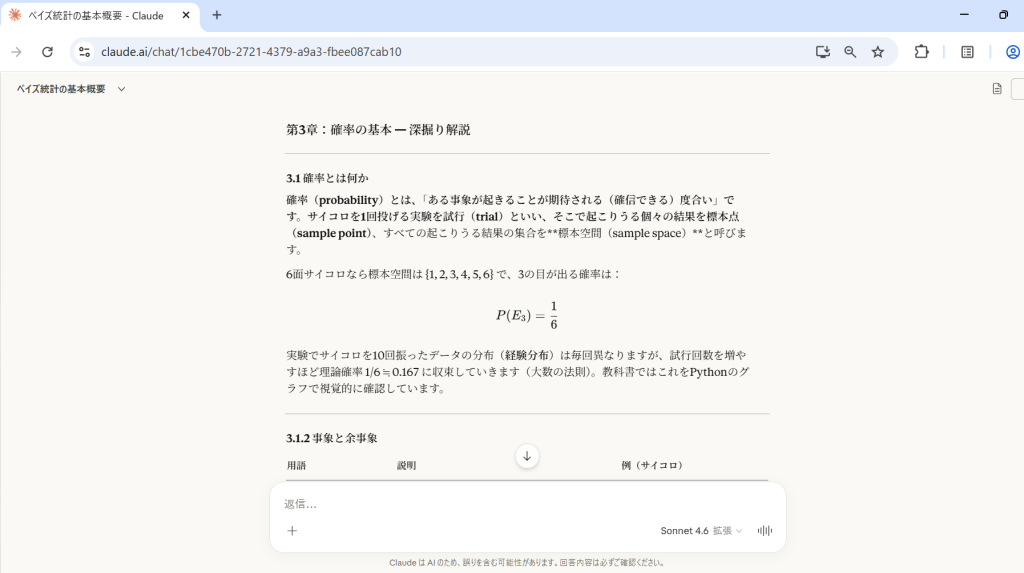
このように複雑な専門書を1冊そのまま読み込んでも、人が書いたような自然な文書で矛盾なく要約できます。論理構成がしっかりしていて、最小限の手直しで資料として使用できると感じました。
一方で数値の正確な計算や画像や複雑なレイアウトの読み取りは、やや不得意な傾向があります。精度の高い回答を得るためには、読み込ませる前にPDFのテキスト選択が可能かどうかを確認し、必要に応じてテキスト形式で書き出したものを入力するなどの工夫が有効です。
\時短で情報をインプット/
Perplexity
- URL:https://www.perplexity.ai
- 特徴:AI検索エンジン
- 強み:PDF+Web情報を組み合わせて回答
特長
検索機能と複数のAIモデルを融合させた、対話型検索エンジンならではのアプローチが光ります。最大の特長は、自炊したOCRデータを参照しつつ、リアルタイムの外部情報を照合・補完できる点にあります。
さらに、回答には必ず引用元のリンクが明示されるため、情報の信頼性を手軽に確認できるのも大きなメリットです。複数の情報源を横断的に読み解くことで回答が偏りにくく、多角的な視点からの深い調査やリサーチを実現します。
こうした強みを活かすことで、過去の書籍や資料の内容を最新の動向と照らし合わせることはもちろん、学習用の問題作成や多言語資料の解説まで、実に幅広い用途で活躍してくれるでしょう。
👉 おすすめ用途
- 調査・リサーチ
- 最新情報との比較
実際のPFDをアップロードし検証
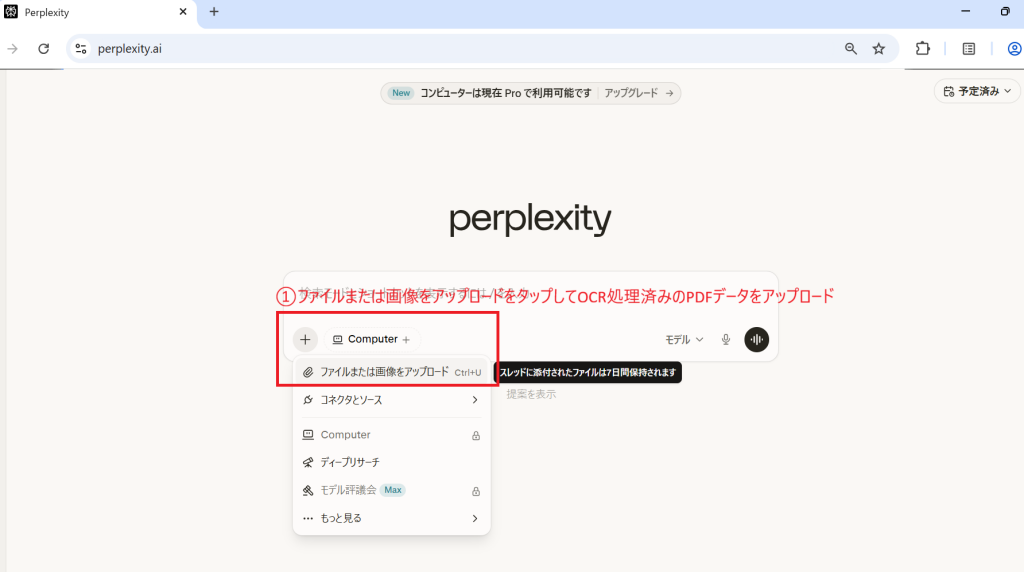
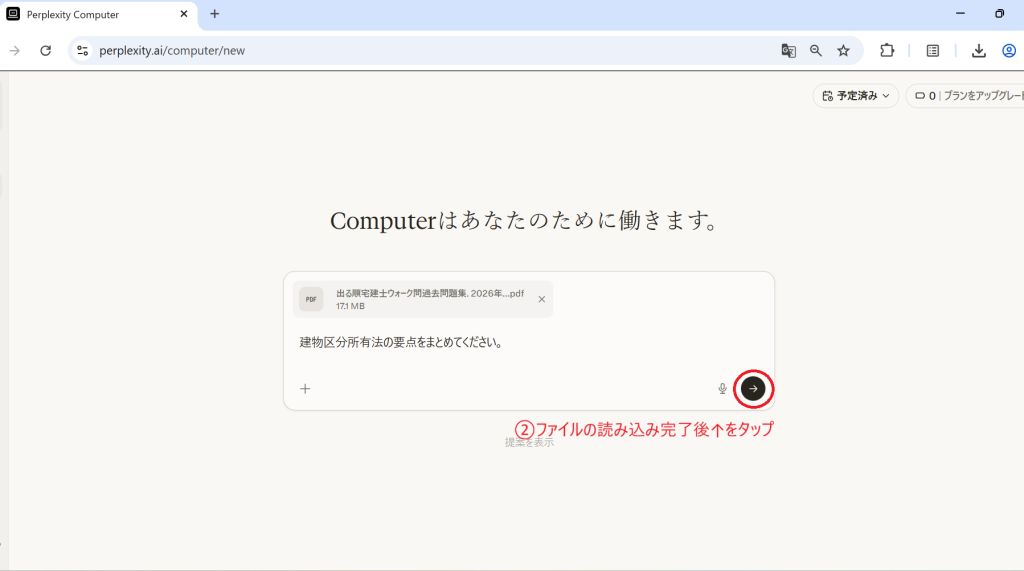
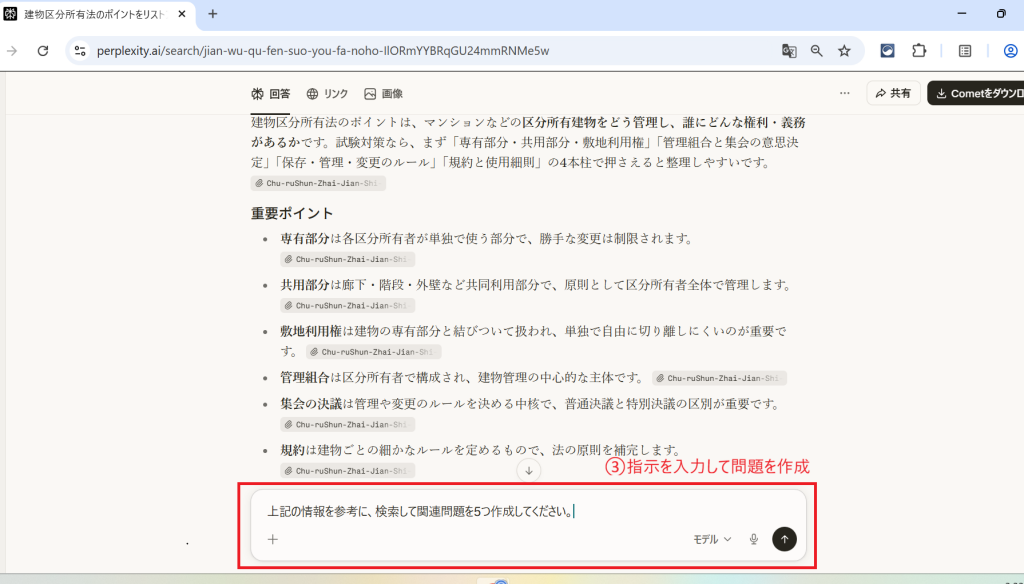
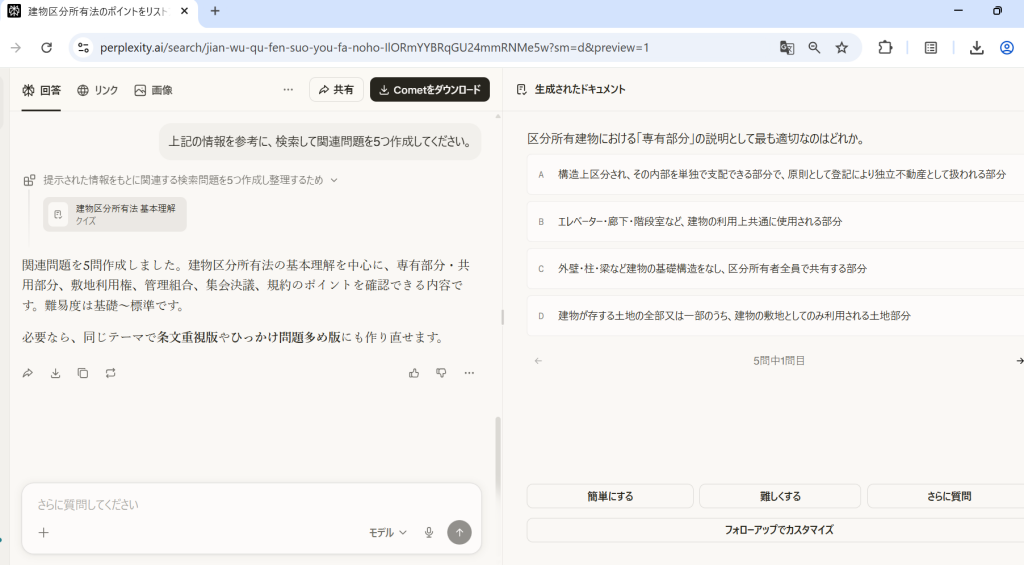
このように情報と引用元がセットで表示されます。引用元をタップすればプレビューで出典元のページが表示されるので、参照した部分の確認が簡単です。自炊OCRデータの内容をもとに情報の補完やリアルタイムの最新情報を検索でき、一歩進んだ情報収集を可能にします。
学習用問題の作成や最新Web情報との比較・検証、多言語資料の翻訳・解説など、さまざまな用途に使用できるのが魅力です。ただし、検索特化なので出力内容は端的(事実のみ)になりやすく、深い考察には向いていません。
\時短で情報をインプット/
Humata AI
- URL:https://www.humata.ai
- 特徴:PDF特化AI
- 強み:高速な質問応答
特長
PDFなどのドキュメント活用に特化したこの文書分析プラットフォームは、アップロードしたファイルをもとに、要約や質疑応答、横断検索を高速かつシームレスに実行できるのが特長です。
大きな魅力は、左側にチャット、右側にPDFを配置した視認性の高い二分割レイアウトにあります。この画面構成により、引用元の確認と分析作業をスムーズに同時進行できるだけでなく、回答の根拠となった箇所には自動でリンクが付与されるため、数字をタップするだけで該当ページへ瞬時にアクセスできます。
さらに、複数ファイルの同時アップロードにも対応しています。PDFの精密な読み込みと分析に特化しているからこそ、精緻な資料の品質管理や、膨大な文献調査を効率的に進めるための最適なツールと言えるでしょう。
👉 おすすめ用途
- PDF単体の分析
実際のPFDをアップロードし検証
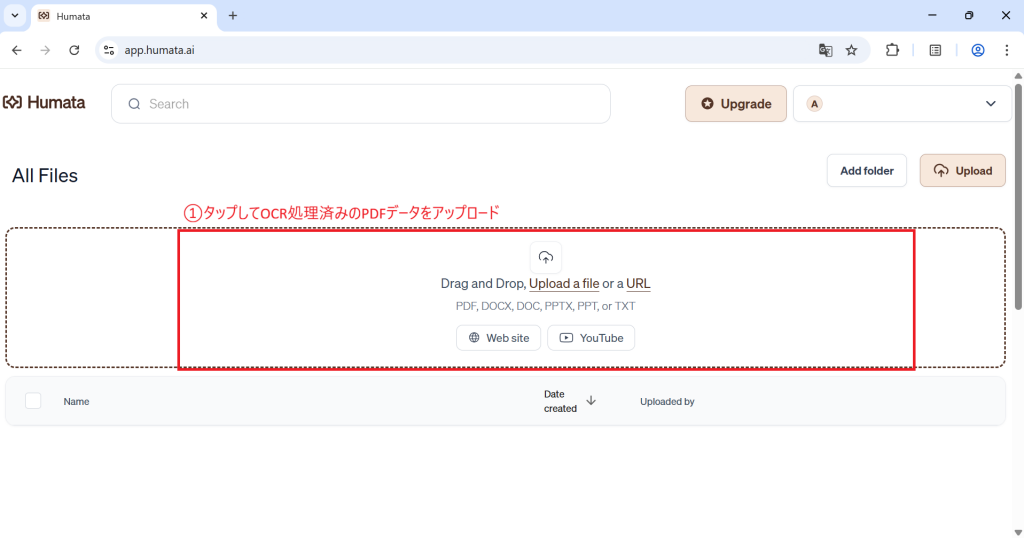
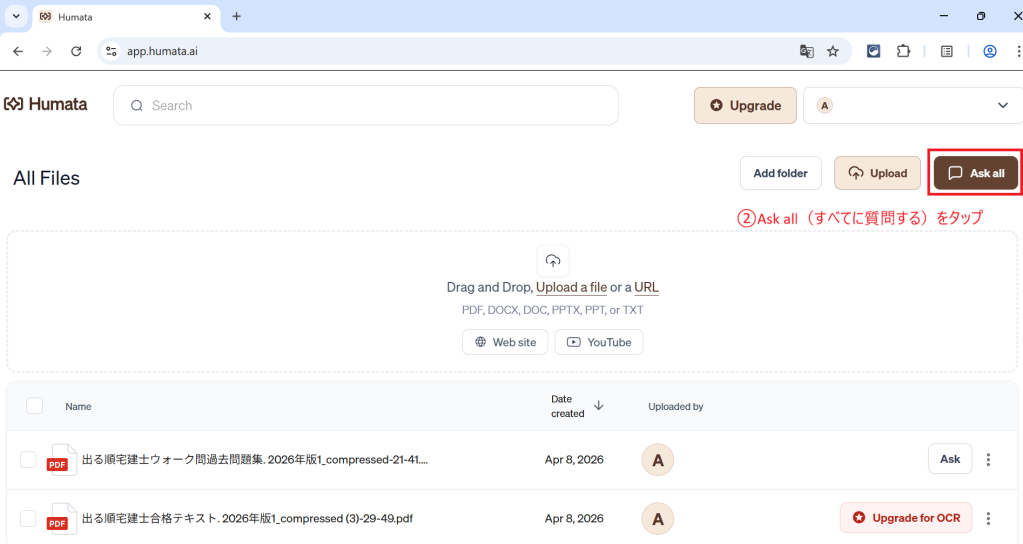
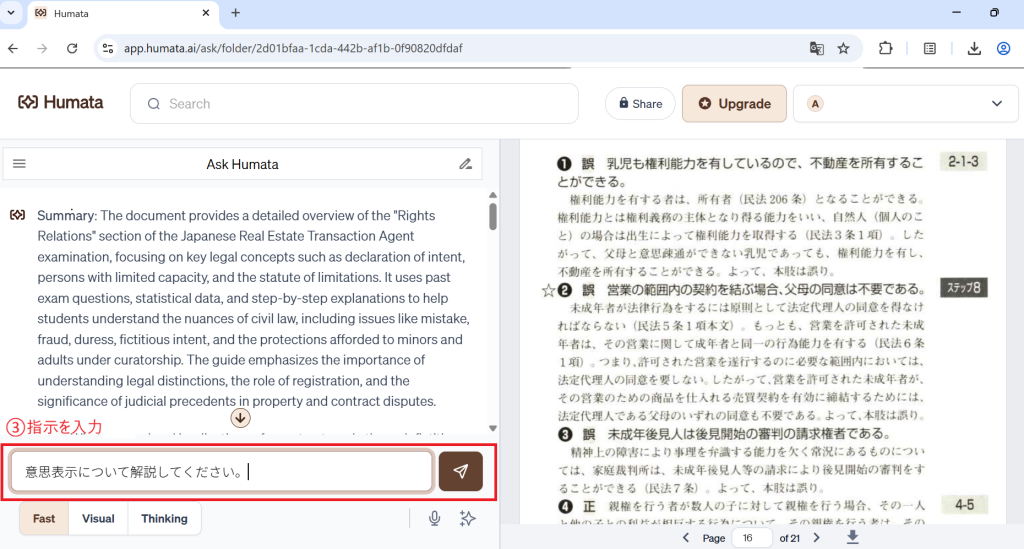
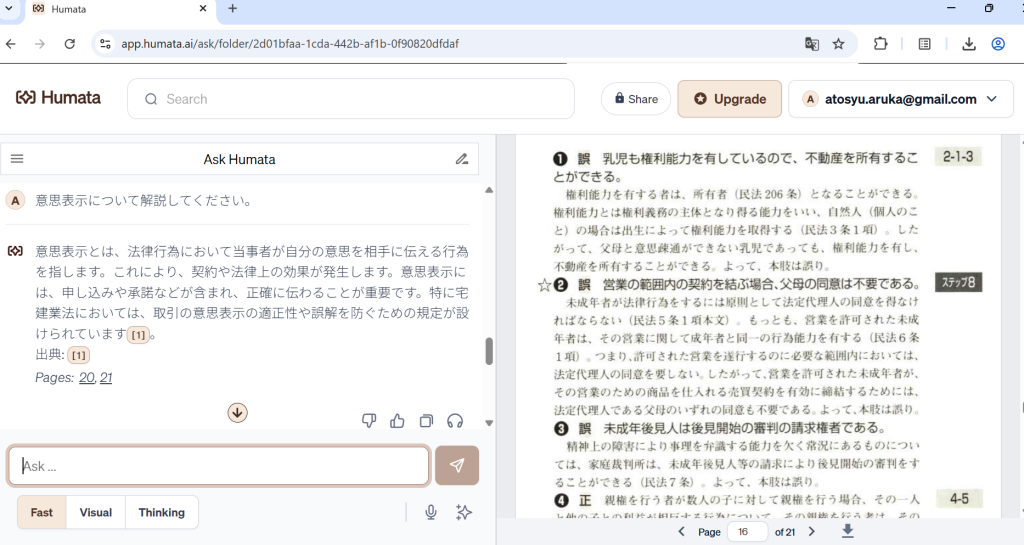
このように画面は左側にチャット、右側にPDFが表示される二分割レイアウトのため引用元の確認がしやすく、回答もスピーディーです。数字をタップするだけでそのページにジャンプできるので、いちいち探す必要がありません。複数のファイルを同時にアップロードでき、プレビューを参照しながら要約・検索が行えます。
一方で日本語の精度はやや低く、指示の解釈や文脈理解は不得意です。上記のような複雑な日本語を含む専門書だと、一部情報が正しく読み取れないこともありました。Web検索に対応しておらず、参照できるデータはアップロードしたPDFの範囲内に限られる点にもご注意ください。
\早速自炊を依頼してみる/
Gemini
- URL:https://gemini.google.com/
- 特徴:Googleサービスとの連携、マルチモーダル機能
- 強み:圧倒的なコンテキストウィンドウ
特長
テキストや画像、音声といった異なる形式のデータを同時に処理できる「マルチモーダル対応」が大きな強みです。特に上位モデルでは膨大なコンテキストウィンドウを備えており、数百ページに及ぶPDFを複数同時に読み込んでも、文脈を見失うことなく極めて高い長文読解力を発揮します。
また、Googleドライブやドキュメント、スプレッドシートといったツール群とのシームレスな連携も独自の魅力です。AIによる分析結果を即座に業務ドキュメントへと書き出せるため、インプットからアウトプットまでの作業を非常にスムーズに進めることができます。
日々の学習に向けた問題集の作成から、ビジネスの現場における高度な意思決定の支援まで、あらゆるシーンで実務レベルの成果をもたらしてくれる、まさに「万能型」のAIツールと言えるでしょう。
👉 おすすめ用途
- 長文の要約・分析
- Googleサービス連携による業務効率化
実際のPFDをアップロードし検証
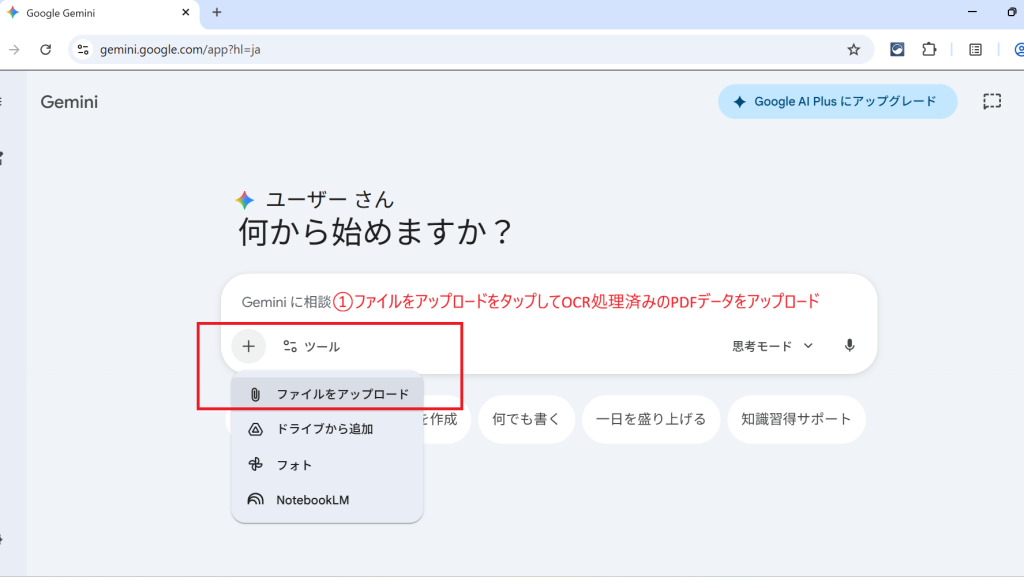
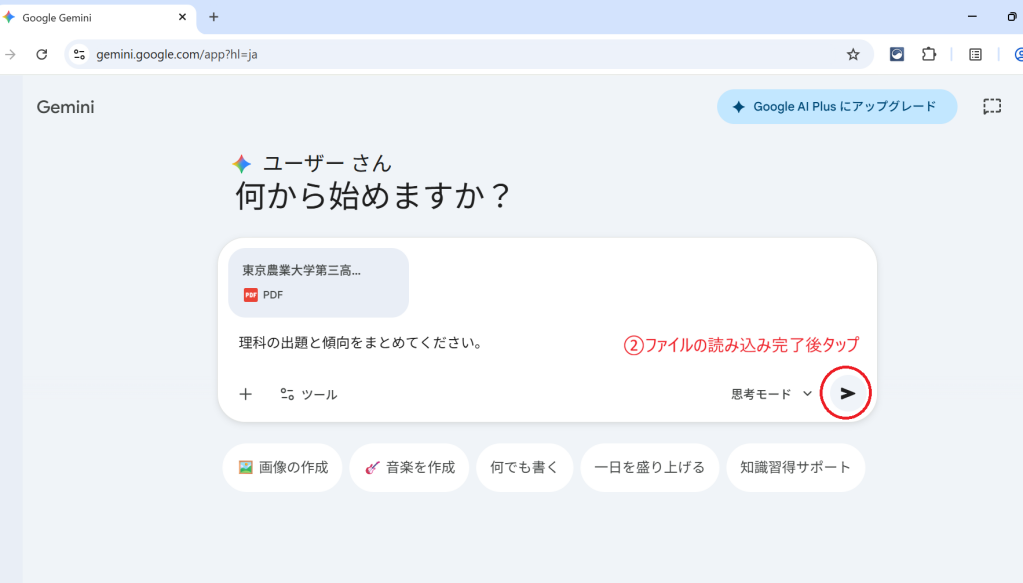
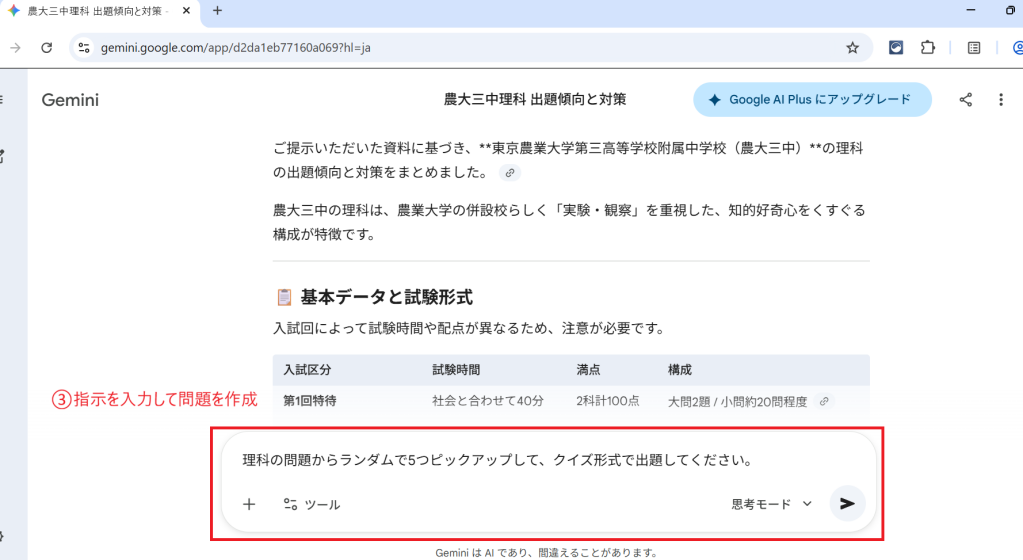
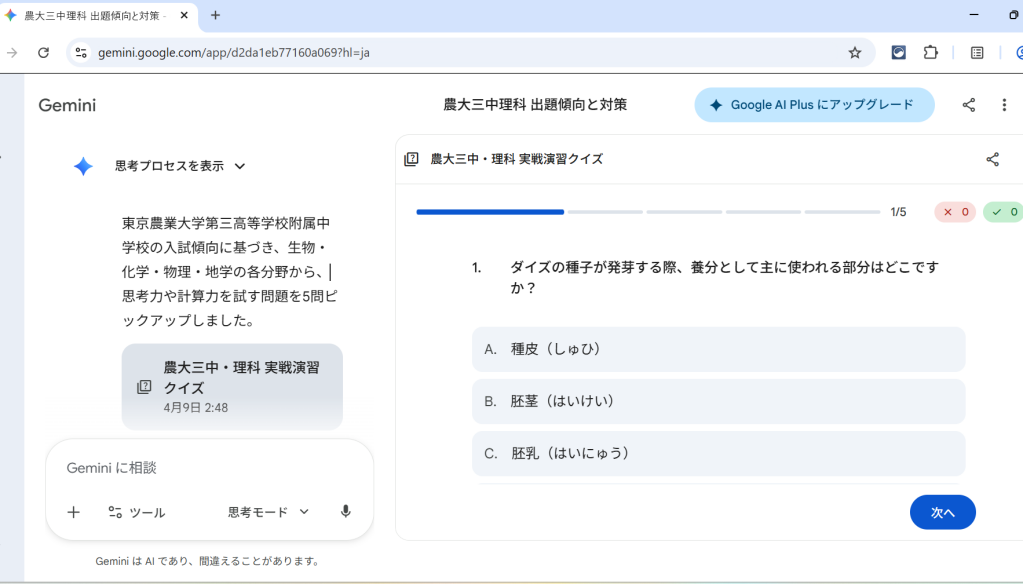
長文読解が非常に得意で、上記のように大きなファイルをアップロードしても情報を適切に抽出できます。上位モデルであれば、数百ページのPDFを複数同時に読み込んでも文脈を失いません。日本語精度と理解力が高く、文脈理解や出力の内容については一定の品質が期待できます。
問題集を読み込ませて新しい問題を作成する、出力内容をGoogleドキュメントやGmailへ直接書き出すなど、学習や実務などさまざまな用途に活用できます。ただし、出力される日本語はフォーマルで固い印象があり、思考モードやProモードなど一部のモードでは生成のスピードが遅いのが気になる点です。
\自炊を試してみる/
Atlas
- URL:https://www.atlasworkspace.ai
- 特徴:複数ドキュメント分析
- 強み:ナレッジ構築
特長
最大の特長は、散在する複数のドキュメントを一つの場所に集約し、ナレッジとして一元管理できる点にあります。さまざまな情報源を登録しておくことで、横断的な質問に対しても関連情報を瞬時に、そしてスムーズに引き出すことが可能です。
画面構成も使いやすさに配慮されており、サイドバーには登録したPDFファイルが一覧表示されます。ファイルの内容とチャット画面を並べて確認できるため、視認性が高く作業効率を大幅に向上させてくれます。さらに、出力される文章には出典や注釈、リンクが自動で付与されるため、引用元の確認もワンクリックで完結する手軽さが魅力です。
Web検索機能による情報の補完にも対応しているため、自炊したOCRデータを含む社内資料を体系的に整理したり、チームの強固なナレッジベースを構築したりするための最適なツールとして活躍します。
👉 おすすめ用途
- 社内資料の整理
実際のPFDをアップロードし検証
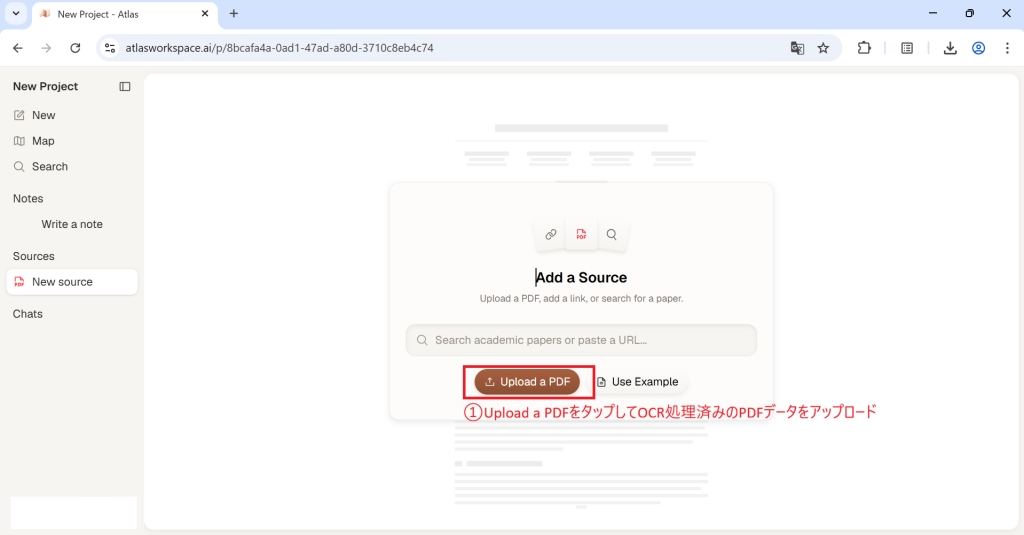
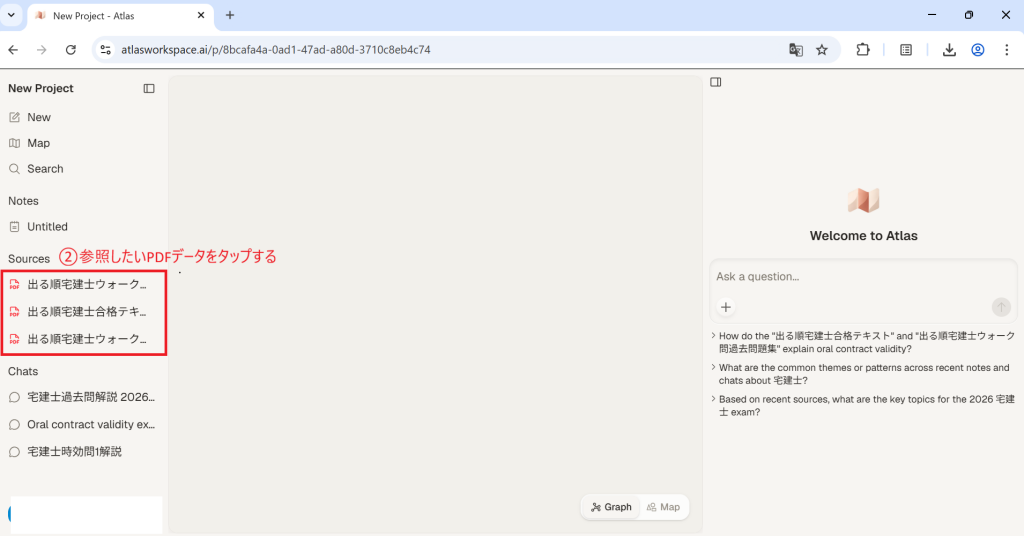
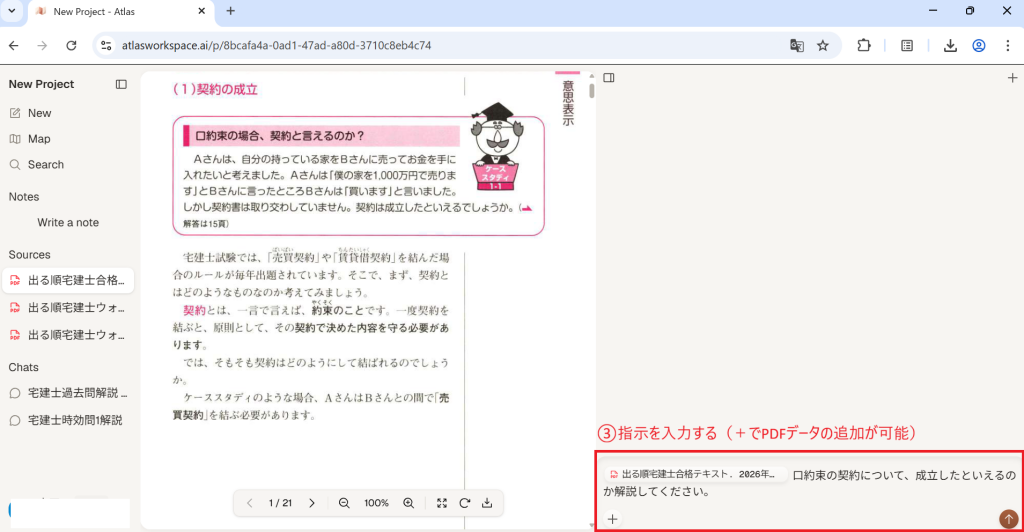
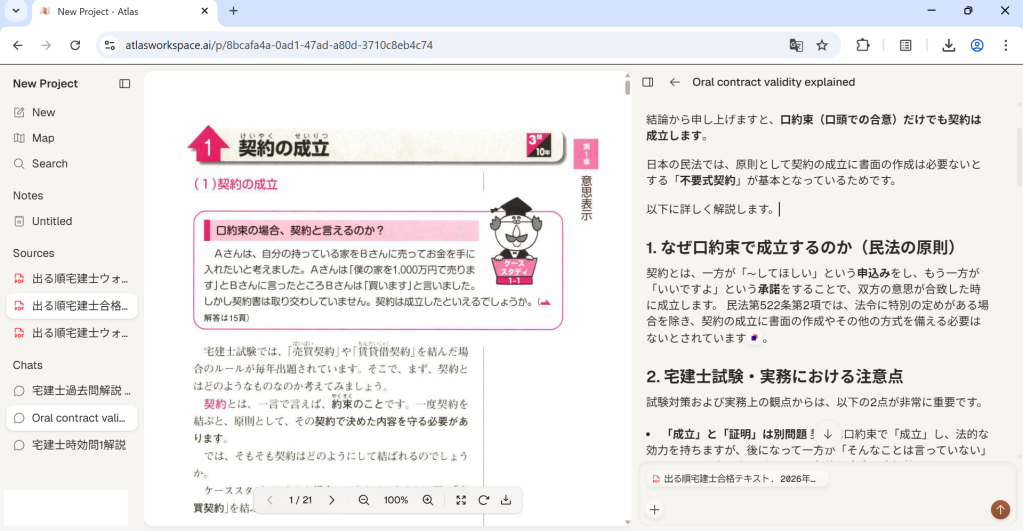
このようにサイドバーに一覧でPDFファイルが表示されるので、必要になったときいつでも確認できます。ファイルの内容とチャットを並べて表示できるため視認性が高く、解説は丁寧で質が高いのが特徴です。
文献レビュー・研究メモ・複数PDFの横断整理に向いていて、Web検索機能で情報を補完することもできます。ただし、専門的な日本語やレイアウトを含む文書の場合、読み取れないことがあるので注意してください。
\書籍を電子化してみる/
AIより重要なのは「OCR精度」
実は最も重要なのは、AIではなくOCRの精度です。
AIによる文章処理の品質は入力テキストに依存するので、OCRの品質が低いと
- 誤認識
- 文脈崩壊
- 誤った要約
につながります。
スキャンした画像データの文字をテキストデータに変換するとき、OCRツールの精度が低いと誤認識や不自然な改行などノイズが発生します。AIツールが文脈を正しく読み取れる品質でPDF化するために、高精度なOCRツールを選びましょう。
英語に特化したOCRエンジンを使用すると文字の認識率が低下する可能性があるので、日本語の複雑な言語体系やレイアウトに対応したOCRツールを選択することがポイントです。
おすすめOCRツール
自炊OCRデータをAIで活用したいなら、高精度なOCRツールを選択しましょう。おすすめのOCRツールと、その特徴を紹介します。
ABBYY FineReader
- URL:https://pdf.abbyy.com/ja/
- 高精度OCR(業務レベル)
ABBYY FineReaderは、日本語を含む198言語の文字認識(OCR)に対応したOCRツールです。あらゆる文書をデジタル化でき、検索・編集・共有・共同作業が行えます。
縦書きや多段組みなど日本特有のレイアウトにも対応しているので、書籍や雑誌の自炊にもおすすめです。スキャンした画像を自動・手動で補正する機能があり、自炊OCRデータの品質を高められます。
Google Cloud Vision
- URL:https://cloud.google.com/vision
- AIベースOCR
Google Cloud Visionは、画像に含まれるあらゆる情報を検出できる画像認識サービスです。画像内のランドマーク(建物・自然物・景観)検出やロゴ検出、顔検出など、文字以外の検出にも対応しています。
認識精度が高く、一般的な書類や手書き文字まで一定以上の基準で認識できます。ただし、日本語特有のレイアウト・文字種についてはやや制限があるので、複雑な帳票や専門的な文書を読み込ませる場合は注意が必要です。
Tesseract OCR
- URL:https://github.com/tesseract-ocr/tesseract
- 無料・オープンソース
Tesseract OCRとは、無料で利用できるオープンソースのOCRエンジンです。100以上の言語に対応していて、適切に設定することで日本語文書のOCR処理ができます。
Pythonなどプログラミング言語から呼び出して自動処理スクリプトを組めば、大量の自炊データの一括処理が可能です。ただし、初期設定が複雑なので初心者にはややハードルが高く、段組みや表組みなどレイアウトも苦手としています。
\本スキャン・自炊代行・書籍の電子化ならSCANBASE/
自炊×AIでできること

自炊OCRデータをAIツールに読み込ませれば、情報活用の可能性は飛躍的に広がります。自炊×AIでできることを、わかりやすく解説しましょう。
PDFの内容を自動要約
AIツールを活用すれば、PDF化した自炊OCRデータの要約を生成できます。内容の全体像を瞬時に把握でき、情報収集の効率化が可能です。要約後に「〇〇についてさらに詳しく」「中学生でもわかる言葉にリライト」など対話を重ねることで、より理解が深まります。
ただし、OCRの精度や元データの品質によって要約の正確性が左右されるため、重要な箇所については原文との照合を行うことが重要です。AIツールに入力する際に引用元のページ数や記述箇所の明示を指示すれば、情報の裏付けが行いやすくなります。
必要な情報だけ抽出
「〇〇に関する情報を抽出」と指示すれば、膨大なOCRデータの中から必要な情報だけ効率的に取り出せます。商品名・単価・数量など特定の項目を抽出して、リスト化することも可能です。
「メール本文」「議事録」などの非構造化データは適切に処理すれば、CSVやJSONなどの構造化データに変換できます。「表記ゆれの修正」や「日付形式の統一」を指示しておくと、その後のデータ分析やシステム連携がスムーズです。
複数資料の比較・分析
PDF化した複数のOCRデータをAIツールに読み込ませることで、比較・分析が可能です。マニュアルの旧版と新版の変更点を抜き出したり、2つの資料の矛盾点・共通点を整理したりできます。
たとえば「品目ごとの単価・納期・保証条件を比較」と指示することで、横断的な比較表を作成できます。出力後に「どちらの条件が有利か」「不足している情報はないか」など深堀りすれば、さまざまな視点から分析できるでしょう。
ナレッジとして蓄積
PDF化した自炊OCRデータを「RAG(検索拡張生成)」に統合すれば、構造化したナレッジベースを構築できます。さらに適切なチャンク(分割)設計と検索精度の最適化により、AIツールを使った正確な情報参照を実現できるでしょう。
適切な埋め込みモデルと検索設計の組み合わせで「セマンティック検索(意味検索)」が可能になり、単なるキーワードの一致ではなく意味的類似性に基づいて関連情報を提示できます。個人・チームの知識管理システムを構築したいなら、「Notion」や「Confluence」など情報共有プラットフォームとの連携がおすすめです。
OCRデータと相性の良いAIを選ぶポイント

目的や用途によって適したAIツールは異なります。OCRデータと相性の良いAIを選ぶためのポイントを、以下にまとめました。
長文データの処理
AIツールには、それぞれ「トークン制限(1回のリクエストで処理できる文字数)」があります。日本語の場合は、漢字1文字が2〜3トークン、ひらがな・カタカナ1文字が1トークンが目安です(モデルにより異なる)。
また、AIには「コンテキストウィンドウ」と呼ばれる、同時に保持・参照できるトークン数の上限があります。これは入力だけでなく出力や会話履歴も含めた総量で決まるため、長文を扱う際には確認が必要です。
トークン制限やコンテキストウィンドウ上限に達すると、正確に処理できなくなる可能性があるので、一度に膨大な長文データを処理したい場合は、対応可能なAIツールやプランを選択しましょう。
ただし、長文データは適切に「分割(チャンク化)」すれば、これらの制限を回避できます。局所的な情報の処理によって精度が向上する可能性もあるため、章ごとに分割するなどの工夫が必要です。
日本語精度と専門用語への対応力
漢字・ひらがな・カタカナが混在し、縦書きや表組みなど独自のレイアウトが多い日本語は、英語と比較して文字認識の難易度が高い言語です。PDF化したOCRデータを読み込むなら、日本語特有の表記やレイアウトに対応したAIツールを選択しましょう。
また、英語中心のデータを学習したモデルでは、日本語の専門文書に対する理解や応答精度が低下する可能性があるので注意が必要です。日本語は主語の省略や文脈依存性が高く、専門領域では用語の意味も分野ごとに異なるため、一般的な事前学習データだけでは十分に対応できないケースがあります。法律・医療・工学などの分野では、用語辞書の活用やカスタムプロンプトの設計など個別の対応が必要です。
なお、AIツールは「もっともらしい嘘(ハルシネーション)」を出力することがあるため、原文と照らし合わせる工程が欠かせません。プレビューなどでPDFファイルの内容を参照できるAIツールもあるので、ぜひチェックしてください。
OCR特有のノイズに強いテキスト解析AI
OCRデータに含まれやすい誤認識や文字欠損(OCRノイズ)は、AIツールの解析精度が低下する原因になるので注意が必要です。文書補完に優れた大規模言語モデル(LLM)なら、多少の誤字脱字があっても前後の文脈から正しい意味を推定できます。
ただし、固有名詞・専門用語・数値の誤認識は自動補正が難しいので、人の目による校正・修正が欠かせません。OCR精度は入力画像の品質(解像度・コントラスト・傾き)に大きく依存するため、OCRツールでPDF化する際には前処理による改善が重要です。
検索しやすい仕組み
AIツールでは、従来のキーワード検索とベクトル検索を組み合わせた「ハイブリッド検索」が主流です。キーワードの一致による全文検索にとどまらず、意味的な類似度に基づいてベクトル検索を行います。
OCRデータは表記揺れが多く、ベクトル検索の性能が検索精度を左右する要因の一つになります。同じ意味でも異なる表現を理解し、適切に関連情報を参照できる、高度なベクトル検索が備わったAIツールを選びましょう。
日本語テキストを扱う場合は、日本語に対応した埋め込みモデルの使用が前提になります。チャンクする場合、小さすぎると文脈が失われ、大きすぎると不要な情報が混じり検索精度が低下する可能性があるので、適切なサイズで分割してください。
実務で使える要約精度
実務で使える要約の定義は、「判断に必要な情報を過不足なく提示できるか」どうかです。AIツールには、文書全体を参照し、論理的な文書構造を保持できる性能が求められます。
一部のモデルでは長いコンテキストの中間や後半部分で要約精度が低下する、「位置バイアス」が報告されているので注意が必要です。何を要約すべきか適切に明示されているほど出力精度は高まるので、求める情報や粒度をプロンプトであらかじめ指定しておきましょう。
OCRデータとの相性がよい入力形式・連携性
PDF・TXTなど、各AIツールの入力形式をあらかじめ確認しておきましょう。PDF形式でのアップロードに対応したAIツールなら、OCR済みのPDFデータをそのまま入力できます。
ただし、入力ファイルのサイズ制限はAIツールによって異なるため、調べておくことが大切です。無料プランだとファイルサイズ制限が設けられていることが多いので、大量の自炊OCRデータを扱う場合は、有料プランへの移行を検討してください。
読み込ませる自炊OCRデータの種類やサイズ、用途によって適したAIツールは異なります。たとえば長文資料をもとにしたドラフト作成ならClaude、情報収集ならPerplexityやGeminiというようにです。それぞれの特徴を比較したうえで、目的にあったAIツールを選択してください。
自炊OCRデータを活用する場合、目的にあったAIツールを選択することが大切です。自炊OCRデータと相性の良い各AIツールの特徴と、基本的な活用方法を紹介します。
特長
テキスト、画像、ファイルを一括で扱える圧倒的な汎用性に加え、日本語の細やかなニュアンスを読み解く精度の高さが大きな魅力です。専門性の高い内容であっても、複雑な文脈を的確に把握し、まるで人と対話しているかのような自然なやり取りを通じて最適な回答を導き出せます。
また、文章のみならず表や数値、構造の理解にも長けており、データの抽出からExcel形式への変換といった実務に直結するタスクも得意分野です。例えば、自炊したOCRデータを読み込ませることで、煩雑な業務資料の整理やFAQ生成も驚くほどスムーズに進められます。
単なるツールに留まらず、会話を重ねて思考を深掘りするほどに情報の解像度を引き上げてくれる、まさにビジネスの頼もしいパートナーと呼べる存在です。
最強構成(結論)
自炊×AIの最適な組み合わせは以下です。
👉 高精度OCR(ABBYY or Google)
👉 ChatGPT または Claude
この構成により、「紙の情報をデータ資産化」することが可能です。
ChatGPTやClaudeは日本語精度が高く、複雑な文脈でも高精度な応答ができます。ChatGPTは要約・分析など日常の業務に、Claudeは長文資料や書籍の処理にというように、目的に応じて使い分けましょう。
高精度OCRと組み合わせて、自炊OCRデータの活用につなげてください。
まとめ
自炊は単なるPDF化ではなく、AIと組み合わせることで「知識活用」へと進化します。
今後は、
- AIで読む
- AIで整理する
- AIで活用する
という流れが主流になります。
要約による全体把握、必要情報の抽出、さらにはナレッジ化による再利用まで、一連の情報処理の効率化が可能です。
ただし、その成果を左右するのはAIツール単体ではなく「OCR精度」と「適切な使い分け」です。いくら優れたAIを使っても、テキストデータの品質が低ければ出力の精度は上がりません。
まずは高精度OCRと、ChatGPTまたは Claudeの組み合わせを試してみましょう。自炊OCRデータをPDF化して、紹介した手順を参考にAIツールで要約や抽出を出力してみてください。
高精度なOCR付き電子化をご検討の方は、
当社の書籍電子化サービスをご利用ください。
SCANBASE:https://scanbase.net/